
DeepSeek模型如何影響AI產業鏈?利好哪些ETF?
在美國科技巨頭爭相擴大資本支出(CapEx)來增加AI基礎設施建設之際,2025年伊始,中國大模型DeepSeek R1模型的推出顛覆了整個科技界和資本圈的認知:AI算力升級不只是擴容,還可提效;AI算力可以平價化。
在DeepSeek模型誕生前,谷歌、微軟、Meta等科技巨頭購買大量半導體晶片來訓練自家AI大模型,「AI燒錢」幾乎是人工智慧產業的固有認知。憑借著CUDA生態、在AI晶片市場佔據80%市佔率的輝達成為最矚目的AI公司。
而DeepSeek模型以極低成本、較少晶片消耗、高性能、創新算法結構、開源等特點「一夜成名」,使得輝達等晶片股暴跌。德銀直呼DeepSeek的誕生是AI的「斯普特尼克時刻」。
AI晶片需求前景突變,AI產業鏈開始重新估值:不需要太多算力的新認識利空基礎算力端,AI平民化利好消費應用端。
但事實真是如此嗎?接下來,本文將探討DeepSeek對AI產業鏈的潛在影響,並尋找其中的投資機會。
全球AI大模型競賽
ChatGPT是全球首個人類級對話係統,其重新定義了人機交互,是AI技術發展的里程碑。它的誕生推動了美國科技巨頭爭相投入資源、研發自家AI大模型的潮流,打響了AI大模型競賽。
目前,最耳熟能詳的模型有OpenAI公司的ChatGPT、谷歌的Gemini、微軟的Copilot或Phi、Meta的Llama、馬斯克旗下xAI公司的Grok、亞馬遜的Nova、Anthropic的Claude、法國公司Mistral的Mistral Large,以及進步飛躍的深度求索DeepSeek和阿里巴巴Qwen模型等。
據知名AI測評網站Chatbot Arena,截止2025年2月底,目前領先的綜合類AI大模型有xAI的Grok 3、谷歌的Gemini 2.0、ChatGPT-4o、DeepSeek R1、阿里巴巴的Qwen 2.5、騰訊的Hunyuan Turbo S等。
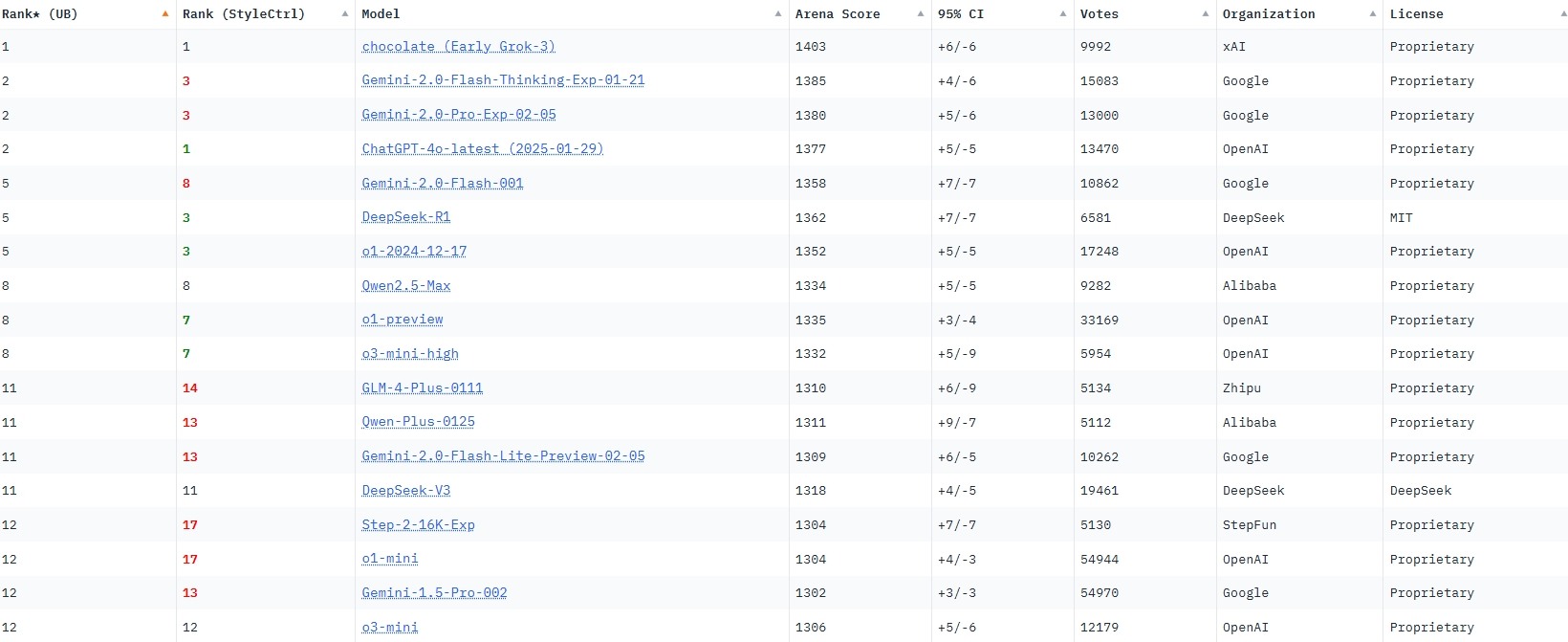
【AI大模型測評榜單,來源:Chatbot Arena】
Deep模型誕生前,資本支出的規模往往代表著發展AI的決心和實力。2024年,微軟、谷歌、亞馬遜和Meta的總資本支出達到2300億美元,這四家公司預計2025年資本支出將達到3200億美元,年增速40%。
儘管關於AI貨幣化能力和DeepSeek模型帶來高額資本支出是否有必要的擔憂依然存在,但這些科技巨頭仍相信,未來AI需求強勁,將繼續投資資料中心等基礎設施。
DeepSeek模型特點
2025年1月20日,深度求索公司發佈了開源推理大模型DeepSeek R1,其在數學、推理、編程等多個任務測試上取得於ChatGPT相當的表現,但將API調用成本降低了超90%。
DeepSeek模型降低算力成本的核心技術是Transformer架構(一種基於自註意力機制的神經網絡架構)和MoE架構(Mixture of Experts,混合專家模型)。
- Transformer架構令模型並行處理輸入序列的每個元素,提升運算效率;
- MoE架構將模型拆分為多個專家子模型,各自負責不同的任務,提升模型泛化能力。
據DeepSeek模型的回答,DeepSeek通過動態訓練優化、輕量化架構設計和高效領域適配的三大創新,平衡了模型性能和落地成本,尤其適用於需要快速響應、多場景適配和高資源效率的實際應用(比如搜索引擎、智能客服、垂直領域AI助手等)。
動態數據調度和課程學習 | 引入基於強化學習的動態數據選擇策略,動態調整訓練數據的難度和分佈,而非以來固定順序或隨機采樣,這樣減少冗雜數據的干擾、顯著提升訓練效率。 |
輕量化混合註意力架構 | 在Transformer基礎上改進註意力機製,結合稀疏注意力(Sparse Attention)與局部-全局混合結構,減少長序列運算開銷。 |
領域自適應和高效微調技術 | 採用模塊化適配器(Adapter)和參數高效微調(PEFT)框架,避免全參數微調的高成本,單任務適配所需算力降低90%以上。 |
【來源:DeepSeek,TradingKey整理】
從成本角度看,DeepSeek R1模型的開發成本約為600萬美元,OpenAI的GPU投入成本每年高達數十億美元。
據統計,OpenAI GPT-4、谷歌Gemini、Meta Llama-3和DeepSeek V3模型的單次訓練成本分別為1至2億美元、2億美元、3000萬至5000萬美元、1000萬至5000萬美元。
DeepSeek團隊披露,在其統計的24小時內,DeepSeek V3和R1推理服務所需的總成本為87072美元/天,若所有tokens按照R1的定價,理論上日賺562027美元,成本利潤率為545%。
DeepSeek的AI產業鏈
從泛化的基本框架來看,DeepSeek產業鏈包括基礎層、技術層、應用層和生態合作。
基礎層(算力與數據) | - 雲端服務:亞馬遜(AWS)、微軟(Azure)、谷歌(Cloud);阿里、騰訊、華為等 - 晶片廠商:輝達(GPU)、AMD、英特爾(CPU);華為(昇騰)、寒武紀(思元)等 - 伺服器廠商:浪潮信息等 - 數據資源:Wikipedia(公共數據集)、Reddit(開源語料);知乎、微博、海天瑞聲(數據標註)等 |
技術層(算法與工具鏈) | - 算法開發:Hugging Face、Github、Meta、OpenAI等 - 模型訓練:輝達、Deepmind;華為(MindSpore)、阿里(PAI)等 |
應用層(行業解決方案) | - 金融:摩根士丹利;螞蟻集團、平安科技等 - 醫療:IBM、Tempus AI;醫渡雲等 - 教育:Coursera;好未來、作業幫等 - 泛娛樂:字節跳動、網易等 |
生態合作與商業化 | - 開發者生態:OpenAI、Anthropic等(競合關係,API服務互補) - 硬體合作:Dell、HPE等 - 終端設備:蘋果;小米、OPPO等 |
【來源:TradingKey整理】
從市場角度看,DeepSeek產業鏈中的晶片廠商和應用端公司最受關註。DeepSeek模型衝擊下,1月27日輝達暴跌17%,市值蒸發創美股史上最大規模,而阿里巴巴和蘋果等公司隨後持續上漲。
摩根士丹利統計,輝達將繼續主導全球AI半導體晶片消費,份額將從2024年的51%升至2025年的77%,屆時將消耗53.5萬片300mm晶片。
業內共識是,應用和平台層將受惠於模型競爭和更低的算力成本。
AI醫療和AI廣告領域在DeepSeek發佈不久後成為熱門炒作板塊:Tempus AI(TEM.US)半月漲超30%,Hims & Hers Health(HIMS.US)股價半個月內翻倍、Applovin(APP.US)幾日漲超30%。
【來源:TradingKey整理】
據調研機構IOT Analytics,在考慮了DeepSeek模型對AI價值鏈的短期和潛在長期影響,贏家可能是最終用戶、GenAI APP、邊緣運算商、數據商等,而輸家可能是AI晶片廠商、大模型廠商等。
明顯贏家 | 終端消費 | 更低成本、輕量級、開放式模型的使用使得AI更普及 |
GenAI APP | 低成本算力思路,更低的API調用成本 | |
可能贏家 | 邊緣運算&數據商 | 模型本地化部署需求增加,數據管理的需求增加 |
可能輸家 | 晶片廠商 | 更低階晶片、更低的成本可能意味著高端晶片需求降低,但也可能推動應用需求增加,並帶動整體晶片需求 |
資料中心相關 | 模型開發效率的提高降低資料中心建設的需求,影響電力、冷卻方案等公司 | |
明顯輸家 | 大模型開發商 | 護城河被打破,尤其閉源模型開發者;低收費或免費模型衝擊高收費模型 |
【來源:IOT Analytics】
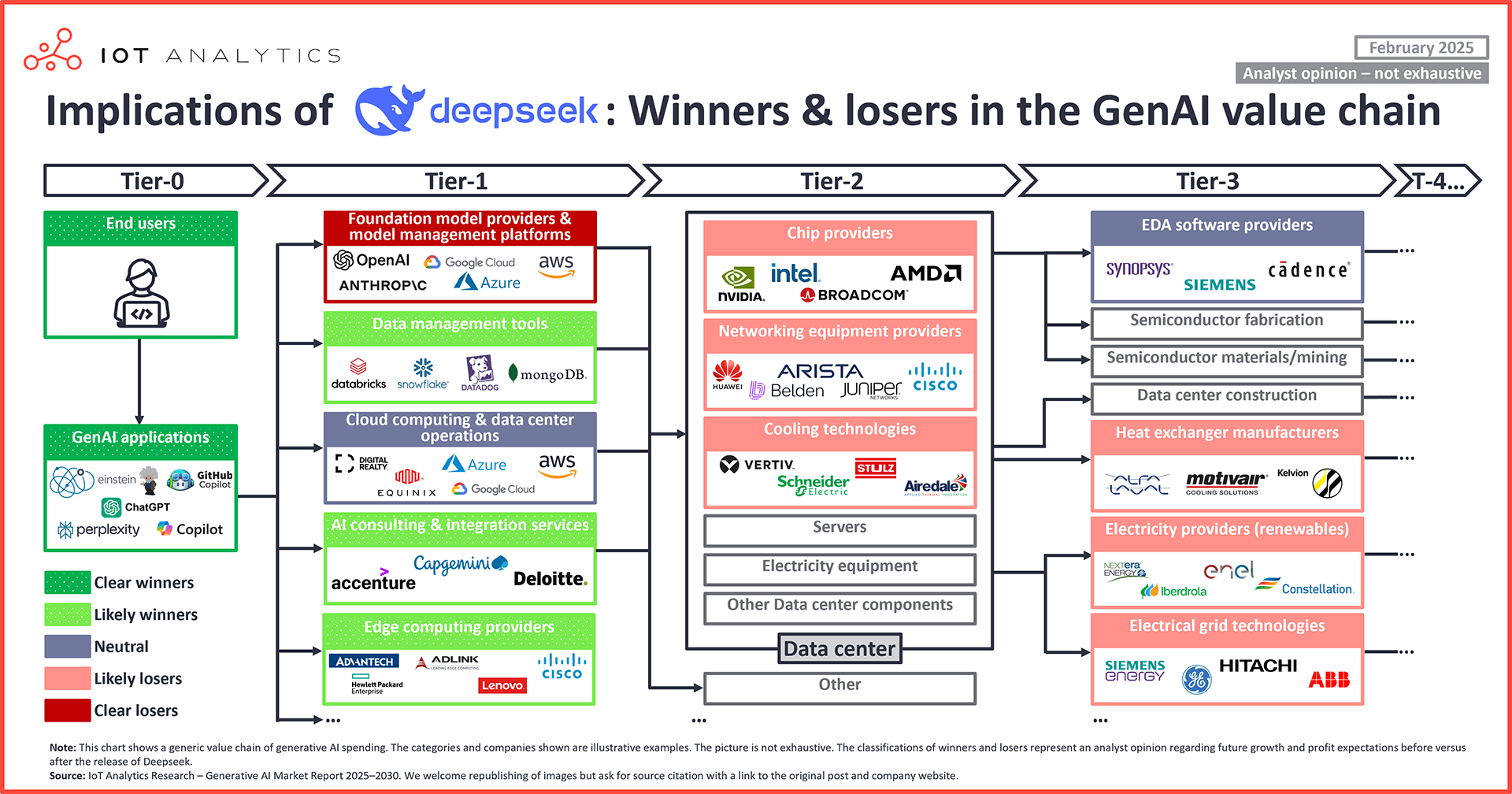
【DeepSeek模型的產業鏈贏家和輸家,來源:IOT Analytics】
DeepSeek對算力影響如何
研究指出,面對高性能算力資源挑戰,「擴容」和「提效」是兩大思路。
- 擴容:最直接的體現就是增加資料中心數量或擴大規模、增加晶片等算力供給。這種思路以OpenAI、谷歌、微軟等公司為代表。
- 提效:優化算力生態,產業集聚;進行知識蒸餾、高效架構等算法創新,優化數據治理等。DeepSeek模型採取這一方向。
DeepSeek模型誕生不久後,輝達等晶片廠商的股價暴跌反映了市場對晶片需求前景轉為黯淡的預期,微軟等巨頭股價暴跌反映了對巨額資本支出合理性的懷疑。
但此後,越來越多分析師和機構開始思考,DeepSeek模型對晶片和資料中心需求的影響是喜是憂?
摩根士丹利指出,中國DeepSeek模型和美國「星際之門」將一起推動全球AI晶片產業鏈需求的新高潮:DeepSeek模型使得中國市場對AI技術的需求迅速增長,AI供應鏈迎新機遇;星際之門計劃將刺激高性能運算(HPC)等AI硬體需求。
輝達CEO黃仁勛表示,DeepSeek的出現點燃了全球科技行業的熱情,該推理模型將來可以消耗更多算力。
美銀預計,2025年雲端運算公司仍會大幅增加資本支出,這反映了強勁的AI需求和現有產能的限制;預計超大規模資料中心運營商資本支出在2025年年增34%,至2570億美元。
DeepSeek潮下推薦ETF
DeepSeek模型對資本市場和行業認識的影響主要有兩點:
- 中美科技實力:中國AI實力被重視,大行看好中國資產重估,可以關註恆生科技相關ETF等。
- 軟硬體協同:算力成本的銳減使得AI競爭焦點從訓練轉向推理,未來AI產業軟硬體協同將進一步增強。除了晶片、伺服器、資料中心外,可以關註應用終端相關ETF。
1、iShares Semiconductor ETF(SOXX):抄底AI硬體
iShares半導體ETF(SOXX)於2001年成立,博通、輝達、高通、AMD和德州儀器是前五大重倉股。2023年至2025年2月底,SOXX上漲70%,2025年內下跌8%。
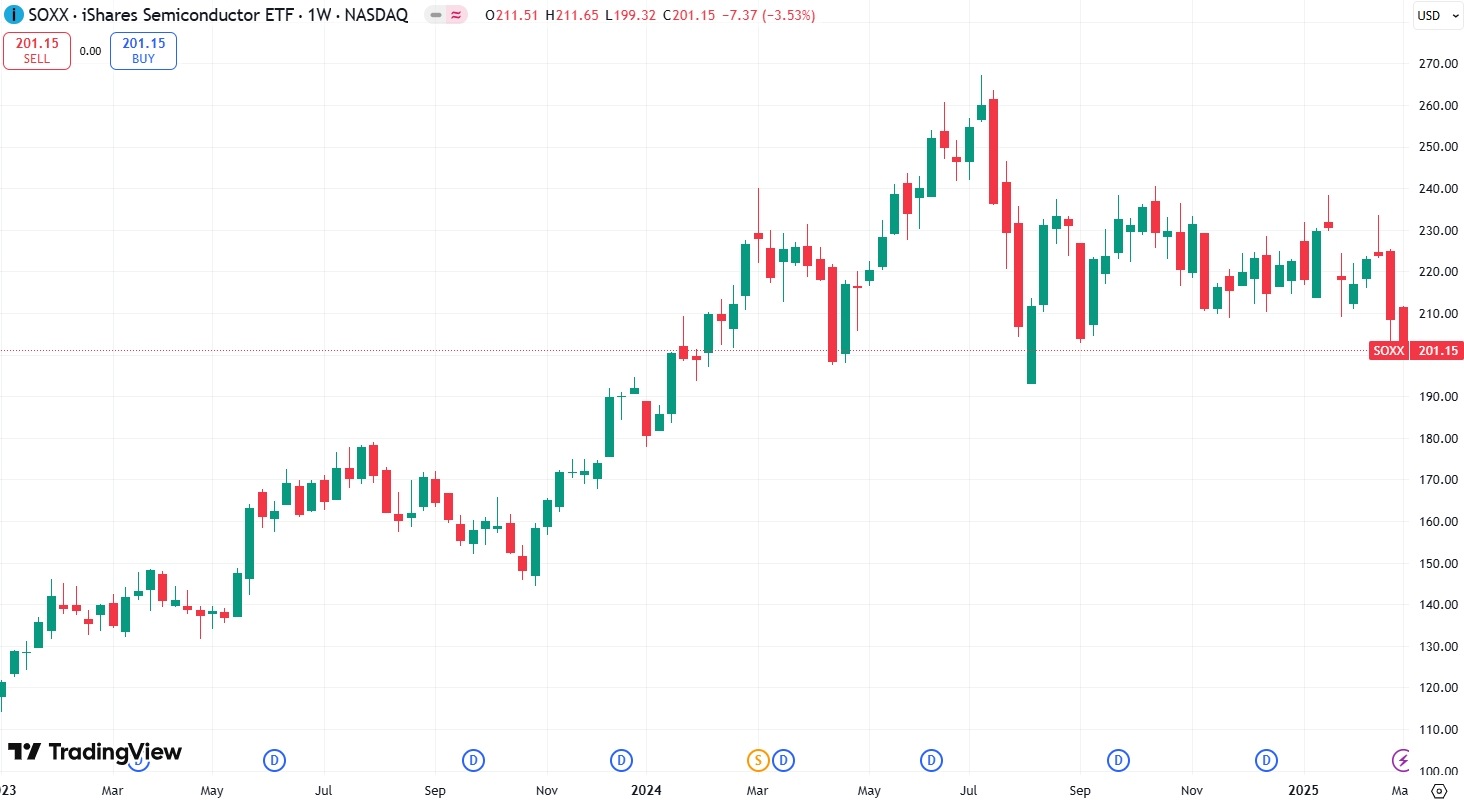
【SOXX價格走勢,來源:TradingView】
DeepSeek的推出令SOXX承壓,但成分公司的前景依然健康。輝達2025財年營收年增114%,利潤年增145%,預計2026財年Q1毛利率超70%。高通CEO表示,DeepSeek模型利多高通,因其晶片可在本地高效運行模型,而非在雲端。
2、Invesco QQQ Trust(QQQ):積極看多科技行業
QQQ ETF,全名Invesco QQQ Trust (QQQ),是Invesco公司推出的追蹤納斯達克100指數表現的基金。2023年至2025年2月底,QQQ上漲85%,2025年內跌3%。
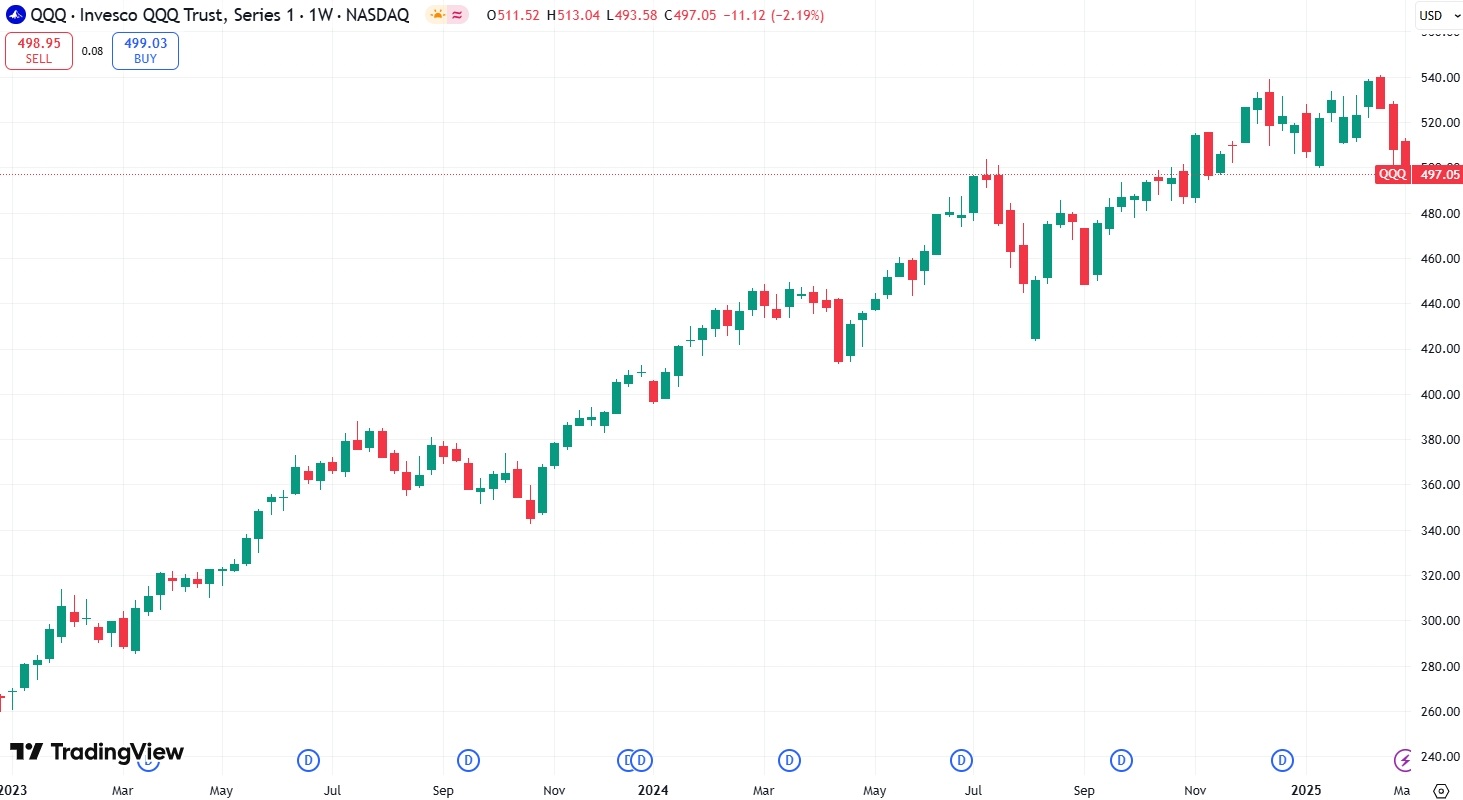
【QQQ ETF價格走勢,來源:TradingView】
前五大重倉股為蘋果、輝達、微軟、亞馬遜和博通,同時投資了特斯拉、AMD、英特爾、Marvell、Costco等公司股票。QQQ ETF持倉不僅包含AI軟體和硬體公司,也覆蓋了消費和醫療領域。
評級機構惠譽指出,若DeepSeek推動AI採用者轉向更永續的支出模式,QQQ ETF內的一些公司將受益:晶片市場分散化將推動AMD和英特爾的前景,業務多元化的博通和Marvell也不像其他競爭對手那樣容易受到AI頭條影響而回調。
3、Invesco S&P 500 Equal Weight ETF (RSP):分散化投資
Invesco S&P 500 Equal Weight ETF (RSP),即景順標普500等權重ETF,對標普500指數的500家成分股公司持有相同權重(0.2%左右),而非按照市值加權。這隻ETF在2023年至2025年2月底期間上漲29%,2025年內漲1%。
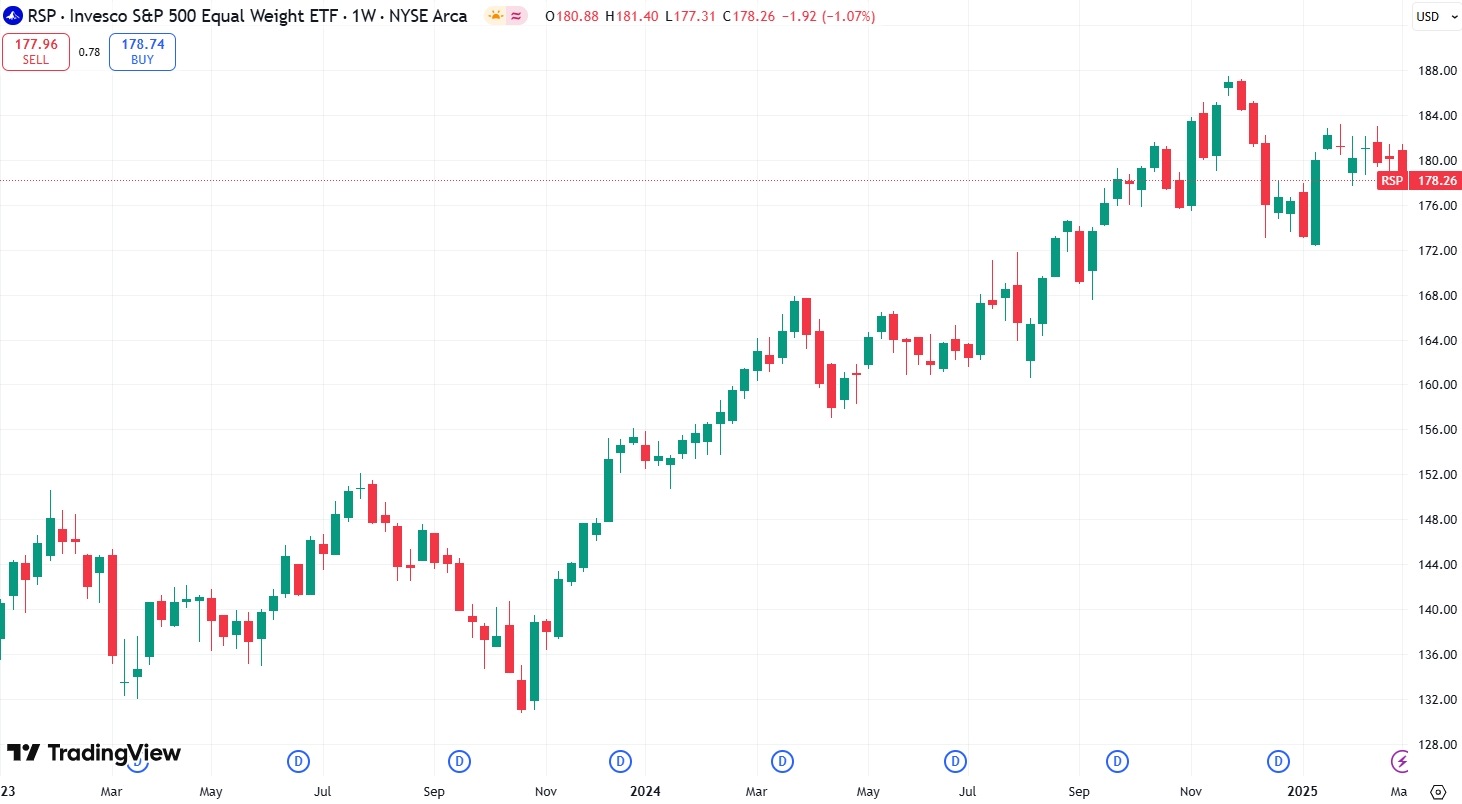
【景順標普500等權重ETF價格走勢,來源:TradingView】
該ETF覆蓋了多個行業板塊,比如工業佔比15.45%、金融14.94%、資訊科技13.72%、健康護理12.63%、非必需消費品9.83%等。
若繼續看好美股大盤,景順標普500等權重ETF不失為一個不錯的選擇:分散風險、中小型股機會、再平衡效應。但也需註意,在科技巨頭主要市場漲勢時,等權重ETF可能會落後於市值加權ETF。
4、南方東英恆生科技指數ETF(3033.HK):中國科技股重估
南方東英恆生科技指數ETF(3033.HK)是全球首個追蹤恆生科技指數的ETF,規模也是最大。
南方東英恆生科技指數ETF在2021年、2022年和2023年分別下跌33.25%、27.42%和9.21%,而隨著2024年中國大規模刺激政策的推出,該指數在2024年實現上漲18.64%。在DeepSeek模型帶動下,2025年初至2月底,該指數上漲超23%。
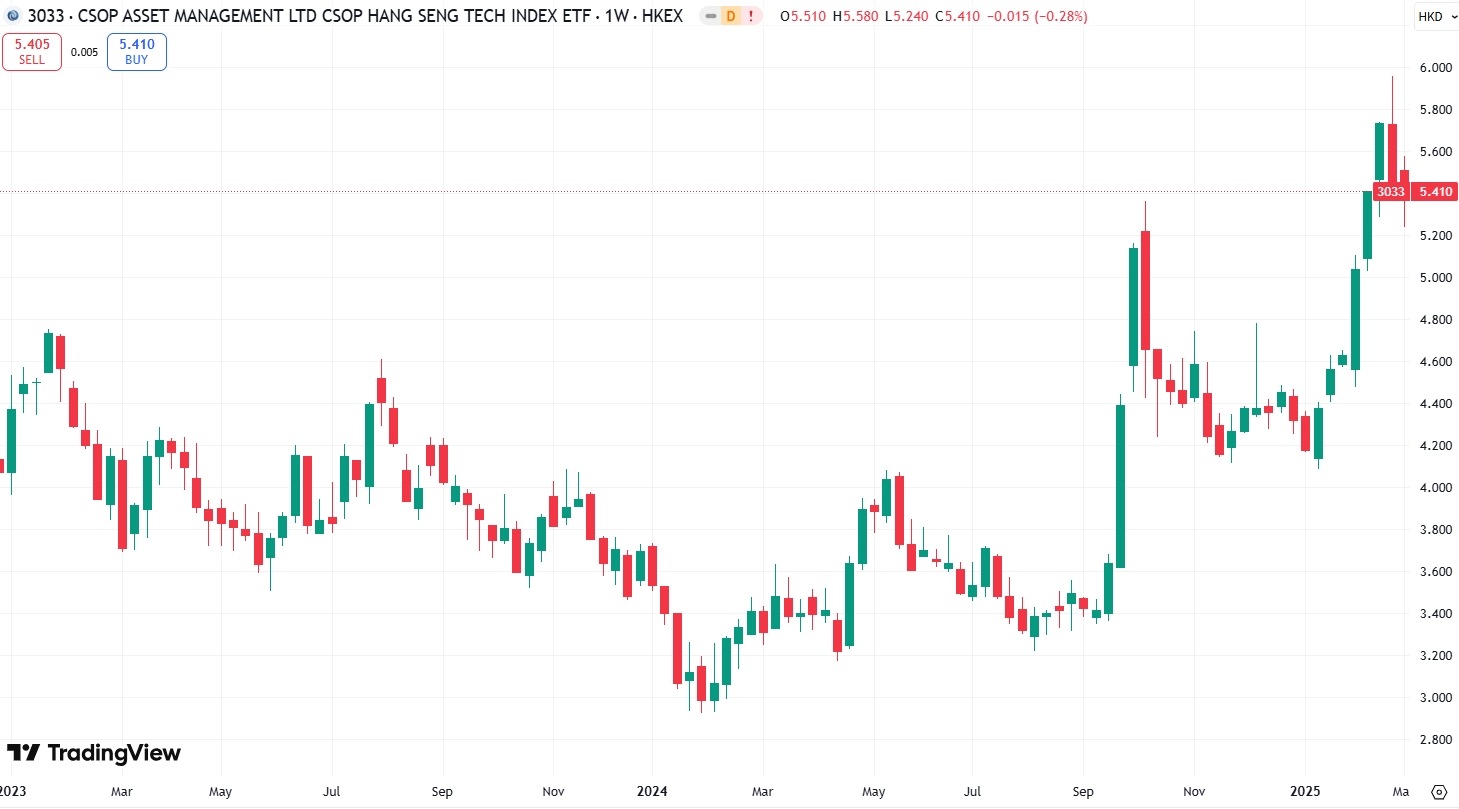
【南方東英恆生科技指數ETF價格走勢,來源:TradingView】
該指數追蹤香港上市的30家頂尖科技創新公司的表現,包括小米集團、京東、阿里巴巴、騰訊、中芯國際、美團、快手、理想汽車、網易和小鵬汽車等。
2025年以來,DeepSeek模型的出現開啟了中國資產重估的敘事。高盛表示,DeepSeek激發投資人加速購買中國股票的熱情。德銀稱,2025年將是全球投資界重新認識中國國際競爭力的關鍵一年。
推薦文章





